Lecture 17: Distributed Memory¶




(Recorded on 2022-05-24)
In this lecture we introduce a new paradigm in parallelism: distributed memory. Distributed memory computing is the easiest way to scale up a system – one just adds more computers. But it is also the most challenging type of system to program and to achieve actual scalability. All of those computers are separate computers and the “parallel program” running on them is an illusion – each computer in the distributed system is running its own separate program. An aggregate computation is comprised from these individual programs through specific communication and coordination operations (which, again, are local operations in each program).
Abstractly, this mode of computation is known as “communicating sequential processes.” The realization of this model in modern HPC is known as “Single Program, Multiple Data” (SPMD) and carried out in practice with the Message Passing Interface (MPI).
Find the value of \(\pi\)¶
In this lecture, we revisit approximating the value of \(\pi\).
We use the following fomula to approximate the value of \(\pi\):
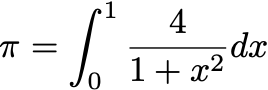
Using numerical quadrature method, we have
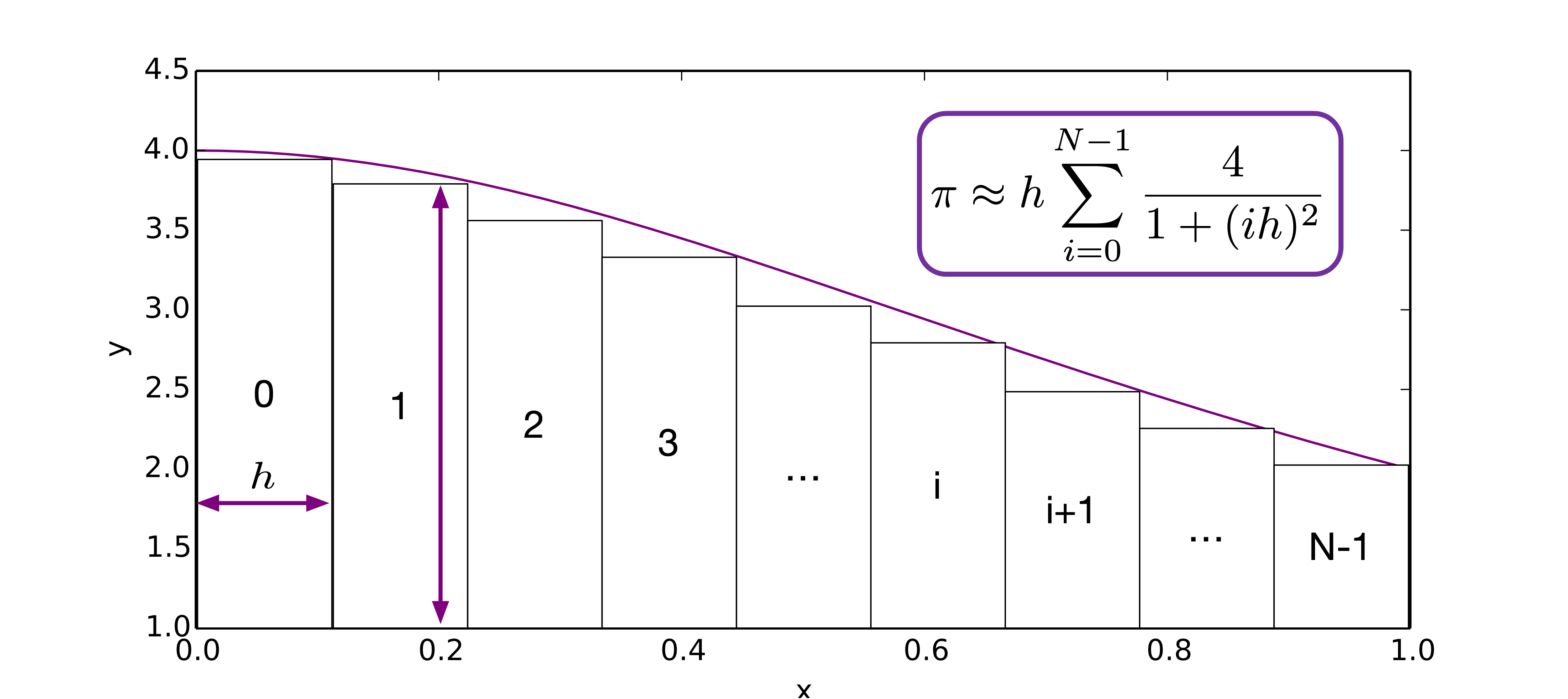
We find that the partial sums are all independent, and can be computed concurrently. How can we parallel it using CSP/SPMD?
We can use one process (with id 0) to get the value of N, and share this value to all the other processes through communication.
Now, every “distinguished replicated process” gets the same N, but it would compute its own partial.
Finally, one process (with id 0) will collect all partials, add them, and print.
Here is the final version we come with up using MPI.

We will cover more about MPI in next lecture, and with more examples.